I have been prototyping a number of LLM-powered AI digital products in the past couple of weeks to further understand how to work with and integrate AI models into my own projects and ideas, including running AI models locally, using AI to organise and make connections between my personal notes, creating a desktop app that reads my emails and draft replies in batch, AI as a dungeon master in a rogue-lite game, and using AI to continuously create new landing pages for A/B testing for my GMAT book. I’ll write about each in separate blog posts. But first, let’s get some AI running on my device that I can use to test my projects.
Running LLM Models Locally
I want to try running LLM models on my local machine. I have a Mac Studio (Apple M2 Max, 32GB RAM). It’s not the most powerful machine you can build to run AI models, but I wanted to know how capable a typical computer you might find on your desk can be. I have found these local models to be sufficiently capable in most instances for the typical writing related tasks, idea generation, and analysis.
Setting Up
The easiest way I found is to simply use Ollama, which is a desktop platform that allows you to run and interact with AI models locally on your device.
Once installed, you run commands through its terminal interface to install models and manage them. (Use Terminal app on the Mac, and Command Prompt or PowerShell on Windows). You can simply type in “ollama run [model name]” to run the model. Here’s the list of commands.
You can find the list of models available on their Models page, which also has commands you can copy and paste into the terminal to run them.
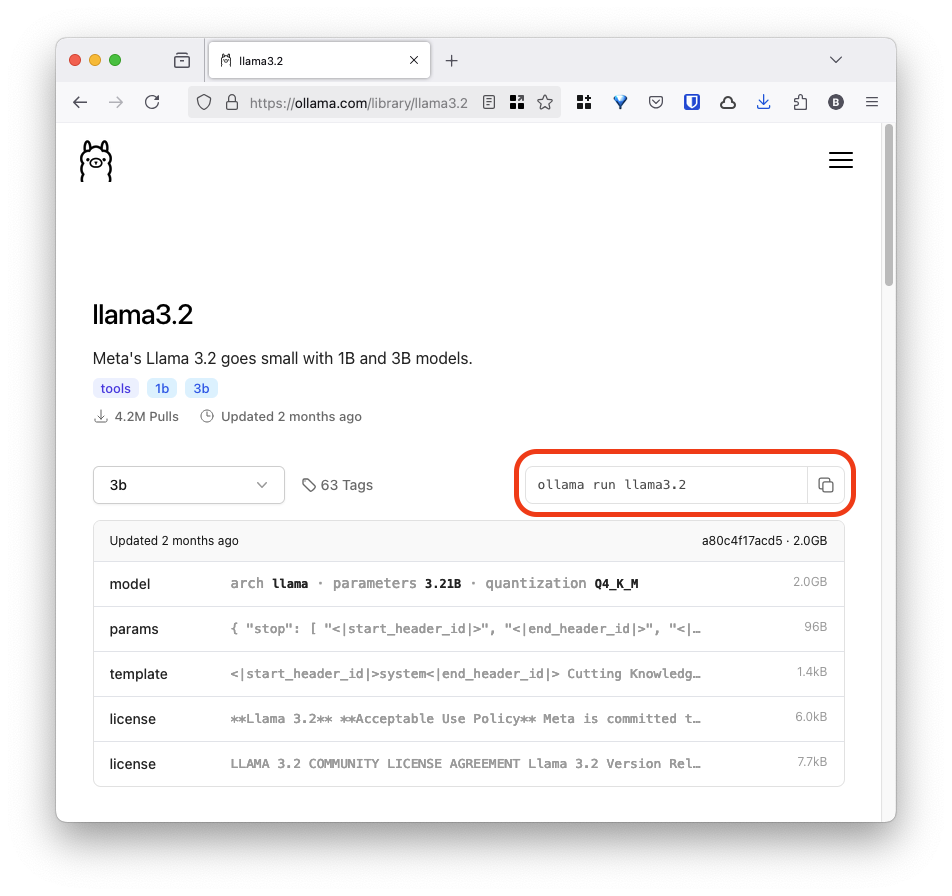
After experimenting with a few different models with different parameters/sizes, I am now running
- llama3.2:latest (3b) for general purpose use
- hhao/qwen2.5-coder-tools:14b for coding agents. (and experimenting with the larger 32b model)
Larger models I’ve tried have been too slow to be very useful. For example, I got a Llama3.3 model (70b-instruct-q2_K) to work on my device but it was painfully slow. Note I have not done any optimisations with them so you might be able to find larger models that work on a computer with a similar spec.
Once you have model ready to go, you can chat with it in the terminal, or use a desktop app that talks to your local model if you prefer a more typical chat interface. Enchanted is the one I use on MacOS, and I will next try Open WebUI for its extensibility. Here’s a list of apps that you can use with Ollama.
What’s even more important perhaps is that these models are now available in a whole suite of apps and tools running on your desktop. Let’s start with a personal notes assistant tool as an example: Building with Local LLM AI Models - Personal Notes with Obsidian and Smart Connections (coming soon)